
Cerebras S-1 Analysis: Wafer-Scale Architecture and the $37B Diluted Valuation
A contracted revenue floor, a single-customer ceiling, and the math in between

Cerebras is having an IPO next week. By all accounts, that IPO is in high demand.
AI CHIPMAKER CEREBRAS SAID TO PLAN IPO PRICE INCREASE MONDAY


At $125 a share, that makes Cerebras approximately a $26.5 billion company. Obviously, as it goes higher, that extends the valuation. (Reuters reported the original $115–$125 range; Bloomberg subsequently reported May 8 that the range is being raised to $125–$135 amid order books reportedly 20x oversubscribed.)

In today’s article, I wanted to take a look at Cerebras. I will discuss what this company is, what this company does, talk about their differentiator in the market, and cover some of their S-1.
What is Cerebras?
Cerebras is, in as few words as possible, a competitor to Nvidia. The company manufactures GPUs, but they do it in a novel way.
When you look at a GPU today the way that Nvidia does it, that GPU is made from a silicon wafer that was cut up into usually somewhere around 70 GPU dies. Cerebras does not cut that wafer up into individual dies. Instead of getting 70 GPUs out of one wafer, Cerebras gets one GPU out of one wafer.

Cerebras’ GPU is called the WSE-3, which is 46,225mm squared. Depending on how familiar you are with measurements, this either sounds like a big or a small number. Consider it in the scale of an Nvidia B200, which is a standard looking GPU. This one is about 58 times the size of that B200 in terms of the area it provides.
The WSE-3 has 900,000 cores, 44GB of on-chip SRAM, and 21PB/s of memory bandwidth. The whole idea here is that by keeping compute and memory on the same piece of silicon, you eliminate the off-chip data movement that can bottleneck GPU clusters. So you can get inference up to 15x faster on open-source models.
Why “No Cut” Matters
The concept of not cutting the wafer sounds simple and perhaps even gimmicky at first glance, but there are actually some real benefits to it.
Modern AI workloads are, more than anything else, communication bound. The bottleneck is not always how fast the chip can compute; it is how fast the chip can talk to memory and to other chips. So, every time you have to move data between chips in a GPU cluster, you pay a latency tax and you pay a power tax.
Whenever you are trying to run a frontier model on GPUs, you have to stitch thousands of them together. With expensive and power hungry switches and networking equipment, a meaningful fraction of your total power budget goes to moving bits around rather than computing on them.
Cerebras’ wafer-scale approach makes most of that problem go away. The model lives on one chip. Compute and memory are inches apart, not feet apart, and the networking layer between the chips is collapsed into the on-chip wiring. This makes it a lot faster than the off-chip equivalent. When Cerebras claims 15x faster inference, it is not software optimization or a marketing benchmark. It is just part of the structural makeup of what they build.
It doesn’t come without its risks, because the trade-off that they had to solve to make this commercially viable was yield. Silicon wafers have flaws, and the bigger the chip, the more likely it is that it has one. Historically, that is why nobody made wafer scale processors. Cerebras has contributed to the field with fault-tolerant architecture that routes around defects on a wafer the way a hyperscale datacenter routes around dead servers. That, plus their proprietary process for connecting dies across the wafer at the fab, is what makes the whole thing shippable.
We should talk about the moat and where that lives. The actual fabrication for Cerebras’ chips happens at TSMC on TSMC’s process technology. Cerebras owns the chip architecture, the fault tolerant routing, the packaging and the cooling work needed to operate the chip, and the software stack co-designed with all of it. That is the real moat for them. It has been built over a decade, but it is design and systems, not the foundry itself. A well-funded competitor with TSMC access could theoretically pursue the same approach, but no one has in roughly 20 years of this being something that was doable. (The Futurum Group’s S-1 teardown has a good walkthrough of the foundry-dependency angle if you want to go deeper.)
OpenAI Anchor
The OpenAI contract is the cornerstone of the whole IPO. In December 2025, Cerebras and OpenAI signed a master relationship agreement that is worth more than $20 billion. This includes 750 megawatts of contracted compute through 2028 with an option to expand to roughly 2 gigawatts for an additional $34 billion. To accelerate the build-out, OpenAI loaned Cerebras $1 billion in working capital that is secured by warrants for over 33 million Cerebras shares.
If this deal works out, there will be dilution, but it is worthy dilution.
The good news for Cerebras is that this is a take or pay structure. OpenAI has to pay for the contract capacity whether they use all of it or not. That converts what otherwise would be discretionary cloud spend into a fixed contractual obligation.
But OpenAI is successful. They have Codex, and Codex will be where they use this compute. Specifically, it is Codex Spark that runs on Cerebras. Codex Spark grew from 600,000 weekly active users in January to 4 million users in May, and there is still a long way to go until you open this up to the 50 million plus paid ChatGPT subscriber base.
On the Cerebras side of things, it is not all rosy. If they do miss milestones, that does allow OpenAI to terminate the contract. The contract also has exclusivity provisions that bar Cerebras from selling to “certain named competitors” of OpenAI, which, most plausibly, are companies like Anthropic, Google, and Meta.
Customer Concentration
One thing that you will see across all the posts about Cerebras is the callout of customer concentration.
It is a very worthwhile call out. In 2024, a company called G42, which is part of the UAE, was 85% of Cerebras’s revenue. In 2025, MBZUAI was 62% and G42 was 24%. That sounds good, right? It sounds like two different companies are now providing revenue. However, both of these companies are UAE affiliated entities and they are related parties, so effectively this money was coming from the same place.
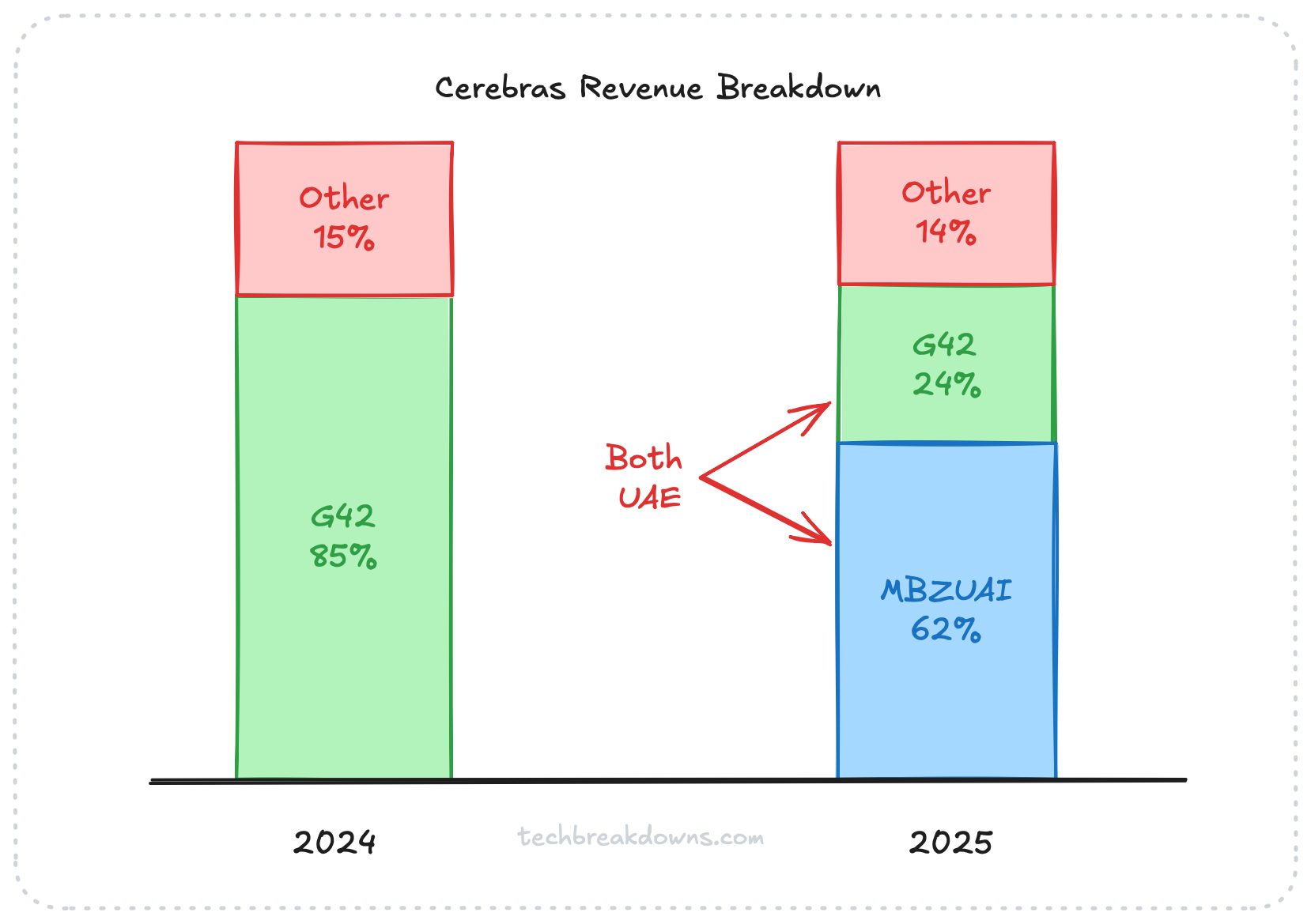
OpenAI does step in and provide at least some breakdown of that concentration for the business. But at the volumes we are talking about from OpenAI, this now becomes a single customer concentration risk.
Cerebras’ chips being available on AWS would add a second whale into the mix that really does start to break down the customer concentration concern, but we still have to wait for those agreements to close. Beyond that, the diversification really depends on Cerebras converting its distribution partnerships and sovereign AI pipeline into named and contracted revenue, which today is forecast and not factual.
Valuation
Right now, the trailing multiple is about 52-56x sales, which is alarming, but it is also basically useless. Cerebras’ revenue is contractually obligated to triple by 2027, which puts us at a forward price-to-sales ratio of about 16 or 17x. This is broadly in line with peers in semiconductors.
Cerebras has that 750 MW contracted with OpenAI. If we look at a competitor like CoreWeave that usually trades around $20M per megawatt, that becomes a $15 billion enterprise value based on the OpenAI relationship alone. That is before you attribute anything to AWS or any other partner cloud that they may be able to work with.
If OpenAI gets up to that full 2 GW, then you are looking at a $40 billion valuation based on that metric.
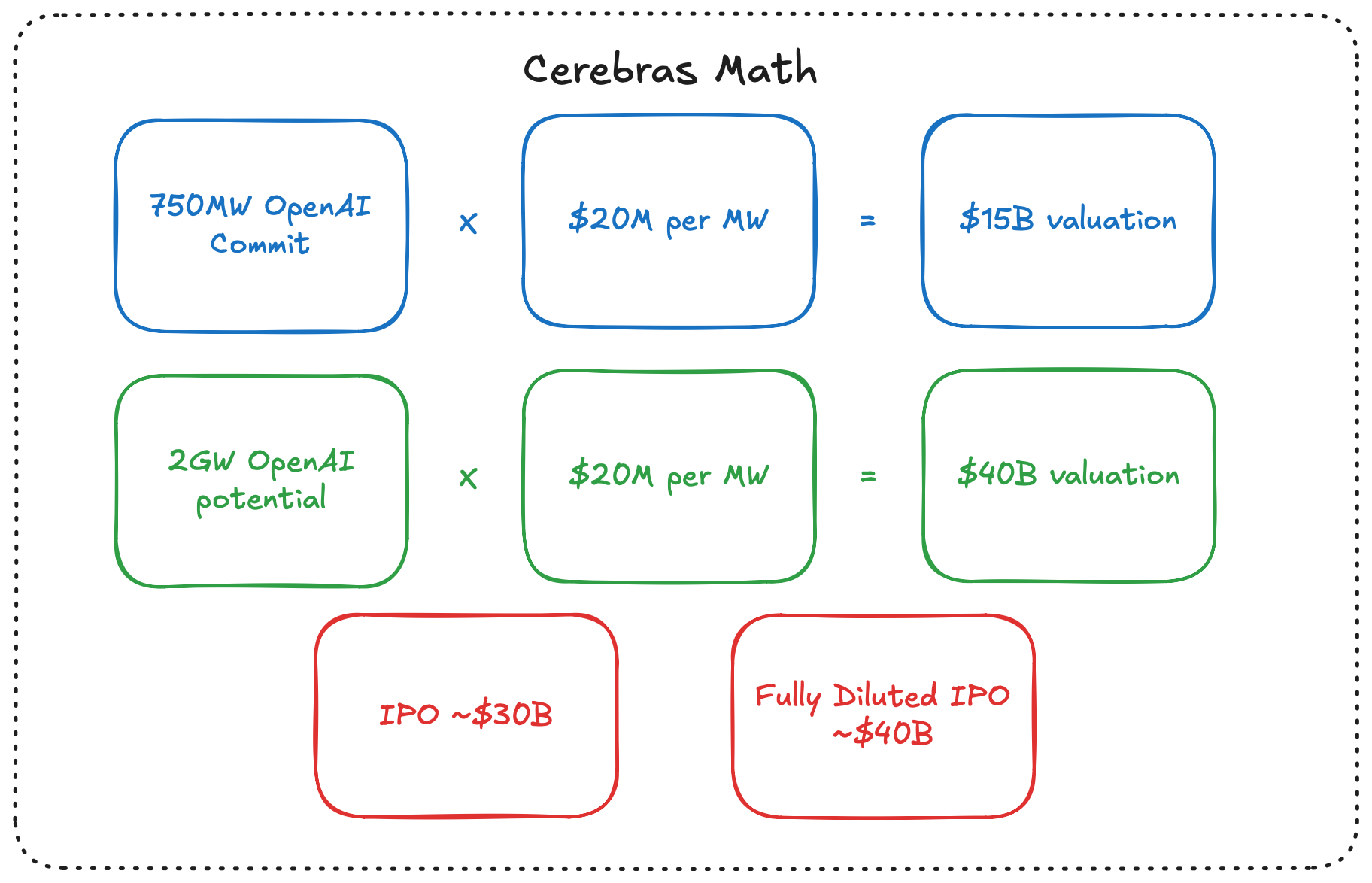
You could absolutely argue that Cerebras deserves more per megawatt than CoreWeave does. CoreWeave leases infrastructure. Cerebras gets the same data center economics, plus the chip IP, plus the software stack. It makes it three layers instead of just one.
Against an IPO market cap that looks to be going somewhere around 28-30 billion dollars, the math somewhat supports the price, but it does not support a meaningfully higher one.
We do have a bit of a dilemma though because the real price tag is likely much higher. Between the 33M OpenAI warrants, the RSUs, and the options, the fully diluted share count for Cerebras comes out closer to 296 million. At $125 per share, that makes the fully diluted market cap about $37 billion.
The EV/MW math at full dilution effectively requires the full 2GW expansion from OpenAI to justify the day 1 price.
The Final Question
Cerebras, at the IPO range it is posting at, is a bet on a specific thesis: that wafer-scale architecture wins the inference layer of AI infrastructure. There is a subsequent bet that owning the chip, the system, and the software stack, plus operating the cloud business on top of it, captures more value per megawatt of contracted capacity than any pure-play competitor can match.
The OpenAI contract means that this is not just pure speculation; it is speculation on top of a contracted floor, which is a somewhat decent place to be.
It is a near given that the IPO will pop on top of an already juiced number and at fully diluted valuations that would give us a market cap meaningfully above $40 billion. That math would require not just the contracted 750 MW, but the full 2 GW expansion option to be exercised. This means the bet is no longer just that “wafer-scale wins inference,” but that “wafer scale wins inference and OpenAI’s compute demand grows fast enough to justify doubling the contract.”
The other open question is whether the OpenAI exclusivity provisions become binding. If named competitors include Anthropic, Google, and Meta, then Cerebras’ serviceable market for the next several years is narrower than the partner list suggests. They can still build a large business. OpenAI plus AWS plus Enterprise plus sovereign AI is real. But the diversification ceiling is lower than the bull case assumes.
What I will be watching:
Does OpenAI exercise the expansion option
Does AWS convert from a term sheet to fully contracted revenue
Is there further diversification a quarter or two after IPO (or is it just OpenAI replacing UAE and we keep single-customer concentration with a different flavor)